
Цель — не “теория про агентов”, а практика: сколько автономии люди реально дают, как меняется поведение по мере опыта, в каких доменах работают агенты и насколько рискованны их действия.
Что именно измеряли и почему это важно
В продакшене автономность — это не абстрактное “может ли модель”, а очень приземлённое “сколько времени и действий ей разрешают без человека”. Anthropic показывает, что латентная способность моделей выше, чем реальная автономия “в быту”: люди и продукты пока ограничивают самостоятельность сильнее, чем требуется по чистым возможностям модели.
Важно: в статье много аккуратных оговорок. Например, по публичному API у провайдера ограниченная видимость того, как устроены агентные системы клиентов, и классификация делается по контексту отдельных tool-call’ов — то есть “внешне автономное” действие может иметь человеческую проверку дальше по цепочке.
1. Агенты работают автономно дольше — и это не «магия нового релиза»
Самый показательный сигнал — не “среднее”, а хвост распределения: самые длинные отрезки автономной работы.
Anthropic фиксирует, что среди самых долгих запусков время автономной работы до остановки почти удвоилось за 3 месяца: с <25 минут до >45 минут. Рост плавный и не выглядит как реакция на релизы моделей, что намекает: дело не только в “умнее стало”, но и в том, как пользователи строят работу с агентом и как продукт поддерживает такие сценарии.
Техническая деталь, которую стоит сохранить в пересказах: в тексте отдельно указано, что речь про 99.9-й перцентиль длительности хода (turn duration) в интерактивных сессиях Claude Code (конец сентября/октябрь 2025 → начало января 2026).
2. Опытные пользователи дают больше автономии — но контролируют иначе
Две ключевые метрики:
- Full auto-approve: у новичков (<50 сессий) около 20%, у опытных (≈750 сессий) — более 40%.
- Interrupt rate: ручные прерывания растут с опытом: ~5% ходов у новичков и ~9% у опытных.
На первый взгляд противоречие (“доверяют больше, но вмешиваются чаще”). На практике это смена тактики надзора:
новички чаще “подтверждают каждый шаг”, поэтому реже нужно дёргать стоп-кран;
опытные чаще дают агенту ехать в автономном режиме — и вмешиваются точечно, когда нужна коррекция курса.
3. Агент умеет сам ограничивать автономию — и делает это чаще человека
Один из самых полезных выводов для дизайна продуктов: надзор — это не только “human-in-the-loop”. Агент тоже участвует в управлении риском.
Anthropic пишет, что на самых сложных задачах Claude Code останавливается, чтобы задать уточняющий вопрос, более чем в 2 раза чаще, чем люди прерывают его вручную.
Практический смысл: хорошие агенты должны уметь распознавать неопределённость и просить ввод — это не “слабость”, а элемент безопасной автономии.
4. Где агенты используются чаще всего
По данным Anthropic, почти половина агентной активности на публичном API приходится на разработку ПО (≈50%). Также виден рост в медицине, финансах и кибербезопасности, но пока не на сопоставимых объёмах.
Главный вывод: нужен пост-деплойный мониторинг, а не только «запреты»
Anthropic формулирует центральную мысль жёстко и полезно: эффективный надзор за агентами требует не только технических ограничений, но и новой инфраструктуры пост-деплойного мониторинга и паттернов взаимодействия, где человек и агент совместно управляют автономией и рисками.
Что это значит “на земле” для бизнеса
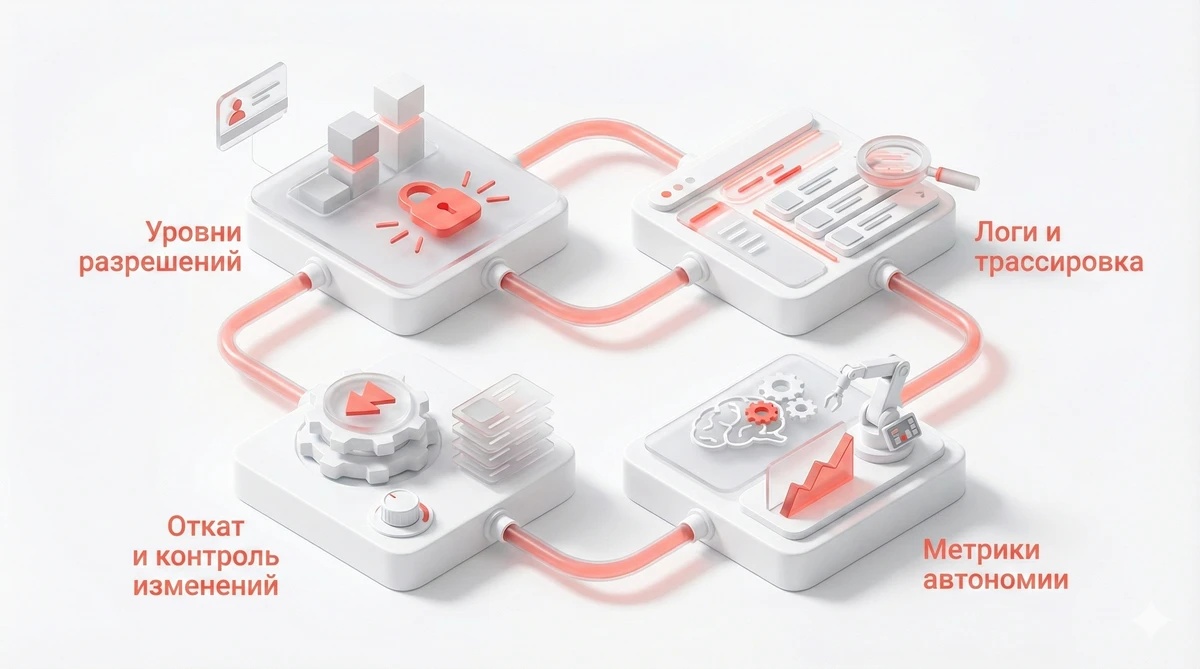
Если вы внедряете агента в процессы (поддержка, продажи, аналитика, разработка, документооборот), вам нужны 4 вещи:
- Уровни разрешений (ручное подтверждение → auto-approve безопасных действий → запрет опасных зон)
- Логи и трассировка (кто/что/когда сделал, какие инструменты вызывал)
- Откат и контроль изменений (чекпоинты, ревью, восстановление состояния)
- Метрики автономии (время без вмешательств, доля auto-approve, частота уточнений, риск-кластеры)

Александр Колотов — backend, frontend, devOps и AI-внедрение.
Автор CompanionAI — симбиоз ИИ и инженера. ИИ ускоряет черновики, инженер подтверждает корректность, ограничения и риски.
